-
ML 기초 (3) | KL 발산과 교차엔트로피 | MLE | 패스트캠퍼스 챌린지 21일딥러닝 2022. 2. 13. 21:00

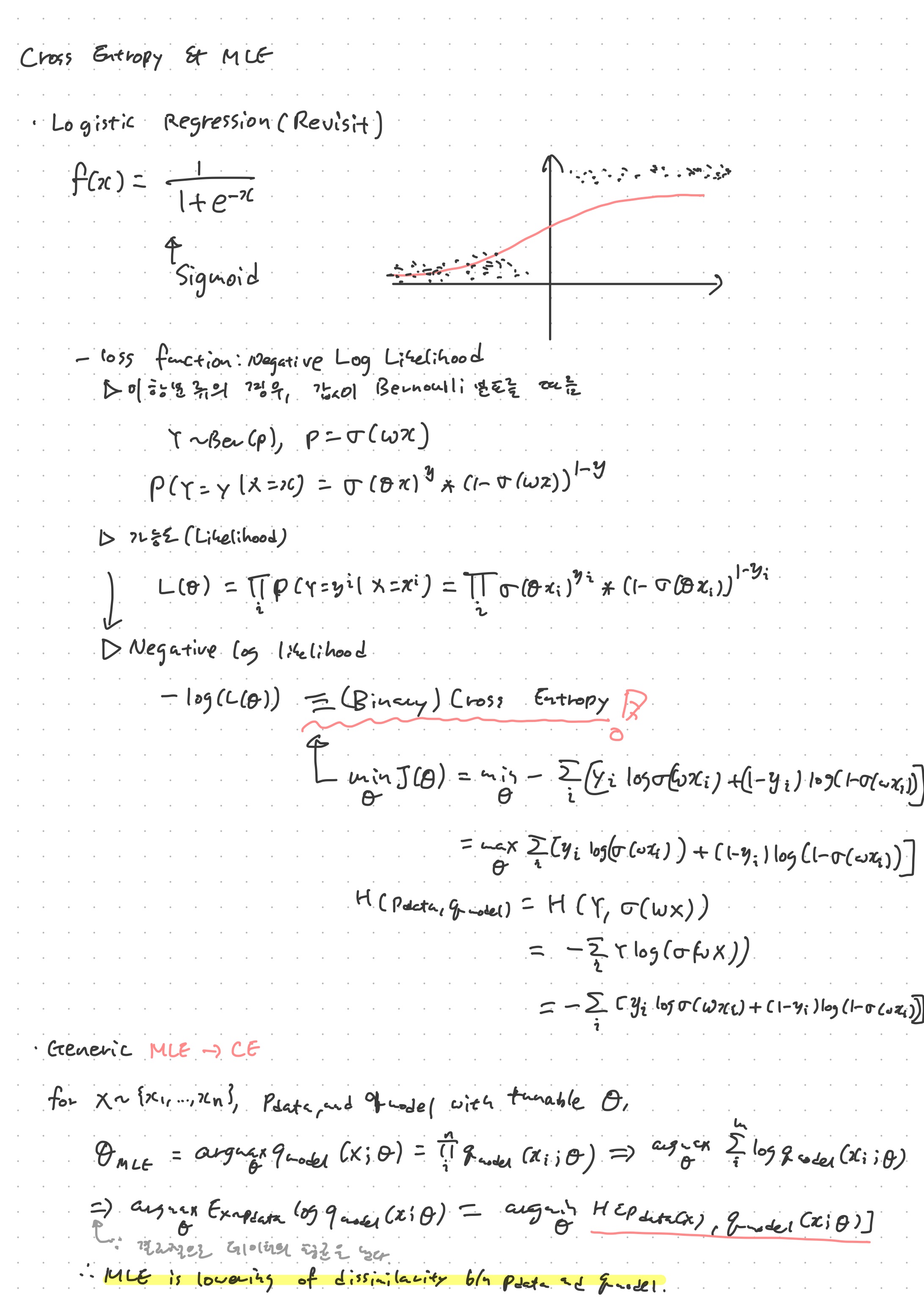
이번 강의에서는 정보량과 여기서 파생되는 개념인 정보 엔트로피를 다루고, KL 발산과 교차엔트로피, 그리고 MLE와 엔트로이 사이의 관계를 다루었다.
이 강의에서 다루는 것과 같은 정보이론은 Shannon이 도입하였는데, 이에 따라 여기서 다루는 엔트로피를 Shannon Entropy라 부르기도 한다. 열역학의 엔트로피와 Shannon 엔트로피 사이에는 통계열역학이라는게 중간 다리를 하는 듯 한데... 자세한 내용은 위키피디아에 자세히 설명되어 있다. 나중에 시간이 나면 찬찬히 읽어 보아도 재미있을 것 같다.
Shannon 엔트로피는 '이산확률변수의 평균 정보량'으로 생각되는데, 이 정보량이라는 것은 어떤 사건이 얼마나 많은 정보를 가지고 있냐를 수리적으로 표현한 수치이다. 쉽게 생각하면, 노트에도 적었듯, 확률이 크면 그 만큼 의미(정보)가 떨어지는 사건이기 때문에 정보량은 작아진다고 생각하면 될 듯 하다. 가령 매일매일 꼬박 학교에 오는 철수가 학교에 왔다는 사건은 크게 정보가 없다. 하지만 드문드문 학교에 오는 민수가(즉, 등교 확률이 낮은 민수가) 학교에 등장했다면 이는 정보가 큰 사건이라 볼 수 있다.
KL 발산은 두 확률 분포의 차이를 정량화 한 것이다. 성질로서는 교환법칙이 성립되지 않고, p와 q가 같을 때에만 0이 되며, 값은 항상 0 이상이다라는 성질을 가지고 있다. 노트 오른쪽에 그래프를 보면 함수값이 음수가 나오는 것을 볼 수 있지만, 이 그래프에서 중요한 부분은 선이 아니라 면적이다. 즉, KL 발산은 0 이상이라는 것과 이 그래프는 서로 위배되지 않는다.
교차엔트로피(Cross Entropy)는, 수학 파트에서 손실함수의 하나로 그냥 소개되었지만, 여기에서는 그 수학적 맥락이 KL 발산과 관련이 있음을 확인해 볼 수 있다.
지난번에 Negative Log Likelihood에 대해 다루었다(노트에 중요한 내용이 반복되어 있다). MLE(Maximum Likelihood Estimation)은 이 가능도를 최대로 하는 것을 뜻하며, 머신러닝의 목표라고 볼 수 있겠다. 이 때, 로지스틱회귀에서 가능도는 (Binary) Cross entropy와 수식이 같았는데, 이를 두고 일반화를 해 보면 결국 MLE라는 것은 cross entropy를 최소화하는, 즉 데이터의 확률분포와 모델의 확률분포 사이의 간극을 최소화하는 것이라고 볼 수 있다. 확률분포의 간극이 최소화된다는 것은 그 만큼 모델이 예측한 확률분포가 수집한 데이터를 잘 예측한다는 뜻이 될 것이다.
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다. https://bit.ly/37BpXi
'딥러닝' 카테고리의 다른 글
순방향 네트워크 (2) | 패스트캠퍼스 챌린지 23일차 (0) 2022.02.15 순방향 네트워크 (1) | 패스트캠퍼스 챌린지 22일차 (0) 2022.02.14 ML 기초 (2) | 패스트캠퍼스 챌린지 20일차 (0) 2022.02.12 ML 기초 (1) | 패스트캠퍼스 챌린지 19일차 (0) 2022.02.11 딥러닝에서의 Extended Jacobian의 활용 (2) | 패스트캠퍼스 챌린지 18일차 (0) 2022.02.10